RApZZVB7_p
Full identifier: https://w3id.org/np/RApZZVB7_px0Ex-8sUyjqtKlPZHv8MXzDTyjSwYSHwx9g
Searching for classes... 
Status
Checking for updates...
Nanopublication
Summary
- estimated semantic networks of animal concepts from montessori-educated children were more interconnected, with shorter paths between concepts and fewer subcommunities, compared to networks from traditional-schooled but comparable children
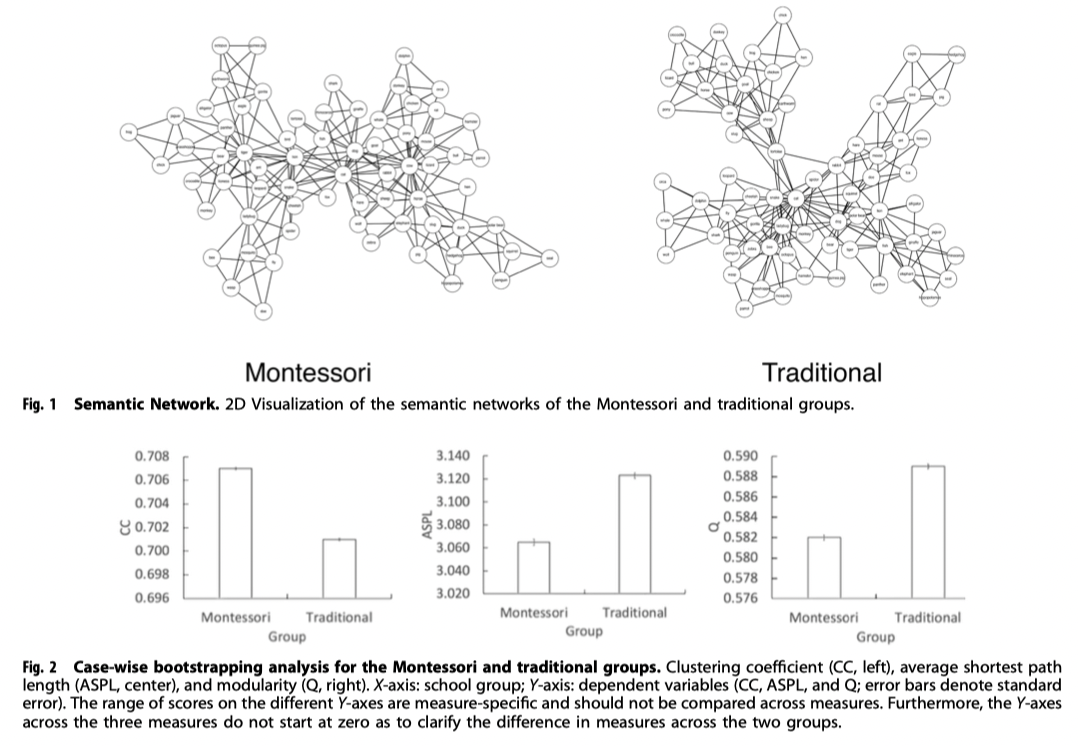 (p. 3: Figure 1, Figure 2)
(p. 3: Figure 1, Figure 2)

 (pp. 2-3)
(pp. 2-3)
- estimated semantic networks of animal concepts from montessori-educated children were more interconnected, with shorter paths between concepts and fewer subcommunities, compared to networks from traditional-schooled but comparable children
Grounding Context
- Who:: compare montessori kids to comparable kids (wrt SES, nonverbal intelligence) from other schooling systems, 67 kids in total
A total of 67 children participated in the current study (Mage =9.31, SD=2.23, 47.8% girls) through the University Hospital of Lausanne researchpool as part of a broader research project on education and neurocognitive development. Children were compensated with a ~30 USD gift voucher for completion of the study. Inclusion criteria were schoolings ystem (participants had to be enrolled in Montessori or in traditional classes from the early years on, in the case of the youngest children, or for at least 3 years), age (5-14 years of age); exclusion criteria were parental report of learning disabilities or sensory impairment. To account for variability in our measures due to nonverbal intelligence, or socioeconomic background, we controlled for between-group homogeneity in nonverbal intelligence (black and white short version of the Progressive Matrices®) and family socioeconomic status (both parents’ education levels (score from 1 to 5) and current job (score from 1 to 4); scores were summed and averaged between both parents (max 9), with higher scores denoting higher SES). (p. 4)


(p. 4)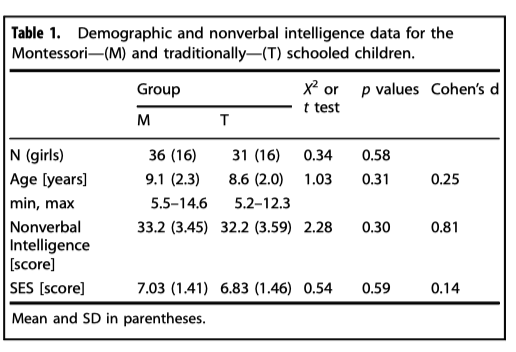 (p. 2, Table 1)
(p. 2, Table 1)
- How:: procedures: do verbal fluency task (name as many animals in 60s), and creativity assessment (standard tasks from Evaluation of Potential Creativity)
Children completed verbal fluency task. Category verbal fluency tasks have been widely used to efficiently assess semantic network organization. Consistent with traditional task administration, each child had 60s to name as many animals as he/she could. Based on previous work in children, we targeted the animal category. Children spoke their responses out loud, which were recorded (and later transcribed) by an experimenter. For each child, fluency data was preprocessed using the SemNA pipeline in R. Repetitions or variation on roots were converged and non-category members were excluded from the final analysis. Number of responses per participant were summed (total number of responses). (p. 5)
 (p. 5)
(p. 5)To assess creative thinking, children completed divergent and convergent creativity tasks from the Evaluation of Potential Creativity. Divergent thinking reflects the ability to think of ideas that differ from one another; convergent thinking reflects the ability to think of a single creative solution. Performance on such creative thinking tasks has been shown to predict both academic*' and creative achievement. In the divergent thinking task, the child was asked to draw as many different drawings as possible from one imposed abstract form (i.e, incomplete shape), within 10 min. The final score was the sum of all valid drawings. In the convergent thinking task, the child had to select three different abstract forms out of eight to create an original drawing that combined them, within 15 min. Three blind judges scored the drawings for originality following the EPoC scoring manual (inter-rater agreement; Krippendorff's alpha = 0.905). Independent t tests were computed on each creativity score (divergent and convergent) to test for between-group differences. Pearson’s correlations were computed between each creativity score and the verbal fluency metrics to test whether creative thinking relates to the quantity and quality of words retrieved from semantic memory. (p. 5)
 (p. 5)
(p. 5)
- What:: measures: clustering coefficient, average shortest path length (ASPL) and modularity (Q) of estimated filtered semantic networks of the animal names from the kids
- network construction/estimation
- dump all responses into a participant-word matrix, so each word is a column, and each participant is a row, and each cell is 0/1 depending on whether participant mentioned the word. this is kind of like a word-document matrix. equate number of nodes across groups
The processed data were transferred into a binary response matrix, where columns represent the unique exemplars given by the sample and rows represent participants; the response matrix is filled out by 1 (if an exemplar was generated by that participant) and 0 (if that exemplar was not generated). To control for confounding factors (such as different nodes or edges in both groups), as in previous studies, the binary response matrices only include responses that are given by at least two participants in each group. Then, to avoid the two groups including a different number of nodes, which may bias comparison of network parameters, responses in the binary matrices were equated, so that the networks of both groups in each sample are compared using the same nodes. (p. 5)

 (p. 5)
(p. 5)
- then for each pair, look at the two "participant vectors" (i.e., the column of 1s and 0s of occurrences across participants)
Next, we computed a word association matrix for each group using the cosine similarity. The cosine similarity is commonly used in related to Pearson’s correlation, which can be considered as the cosine between two normalized vectors. With the cosine similarity measure, all values are positive ranging from 0 (two responses do not co-occur) to 1 (two responses always co-occur). For both groups, each element in the word association matrix, A;, represents the cosine similarity or the co-occurrence between response i and j. (p. 5)
 (p. 5)
(p. 5)
- then draw a filtered network from the similarity matrix using [[mTriangulated Maximally Filtered Graph (TMFG)]]
Finally, using these word association matrices, we applied the triangulated maximally filtered graph TMFGY; to minimize noise and potential spurious associations. The TMFG method filters the word association matrices to capture only the most relevant information (i.e, removal of spurious associations and retaining the largest associations) within the original network. This approach retains the same number of edges between groups (i.e, 3n-6, where n equals the number of responses), which avoids the confound of difference network structures being due to a different number of edges, This resulted in a 68 nodes network with 198 edges for both groups. (p. 5)
 (p. 5)
(p. 5)- method is from [[massaraNetworkFilteringBig2017]]
- dump all responses into a participant-word matrix, so each word is a column, and each participant is a row, and each cell is 0/1 depending on whether participant mentioned the word. this is kind of like a word-document matrix. equate number of nodes across groups
- network metrics: clustering coefficient, average shortest path length (ASPL) and modularity (Q)

- The SemNA pipeline in R was used to compute the CC, ASPL, and Q measures for both groups. Clustering Coefficient (CC) refers to the extent that neighbors of anode will themselves be neighbors (i.e., a neighbor is a node i that is connected through an edge to node j). Higher clustering coefficient indicates a more interconnected semantic network,Average Shortest Path Length (ASPL) refers to the average shortest number of steps (i.e,, edges) needed to traverse between any pair of nodes; the higher the ASPL, the more spread out a network is. Previous research has shown that the ASPL in semantic networks corresponds to participants’ judgments as to whether two concepts are related to each other’*. Modularity (Q) estimates how a network breaks apart (or partitions) into smaller sub-networks or communities. Q measures the extent to which the network has dense connections between nodes within a community and sparse (or few) connections between nodes indifferent communities. Thus, the higher Q, the more the network breaks apart to subcommunities. Such subcommunities can bethought of as subcategories in a semantic network (e.g, farm animals in the “animals” category). Previous research has shown that modularity in semantic networks is inversely related to a network's flexibility. (p. 5)
- network estimation sampling for each group: estimate 1000 case-wise bootstrapped simulated networks from each group (basically, for each group, for 1000 times, grab N-M participants from the group, construct the network, and then compute the network metrics)
- network construction/estimation
- Who:: compare montessori kids to comparable kids (wrt SES, nonverbal intelligence) from other schooling systems, 67 kids in total
- [[ACL Recontextualizing Claims and Evidence Shared Task]]
- Status:: #resultGrounded #methodsGrounded
- Annotator:: [[Joel Chan]]
- ResultGrounding:: [[figure]]
References